Redirecting all kinds of stdout in Python
Python 中的一个常见任务(尤其是在测试或者debug的时候)是在执行某一段代码的时候重定向sys.stdout到某个流或文件.
然而, 简单的”重定向stdout“有时候并不像大家想的那么容易; 因此这篇文章的标题稍微有点奇怪.
特别地, 当你想在 Python 进程中跑 C 代码的时候(包括但不限于, Python 模块实现为 C 扩展), 把它的stdout按照你希望的重定向这件事情就变得有趣了.
这就变得棘手并且把我们带入了文件描述符, 缓冲区和系统调用的有趣世界里.
但是让我们先从基础开始.
Pure Python
最简单的情况是当底层的 Python 代码写入stdout的时候, 无论是通过调用print, sys.stdout.write或其他同样的方法.
如果你的代码全部是从 Python 打印, 重定向就非常简单. 使用 Python 3.4, 我们甚至在标准库中有一个内建的工具来达到这个目的–contextlib.redirect_stdout.
这里有一个用法:
1
2
3
4
5
6
7
from contextlib import redirect_stdout
f = io.StringIO()
with redirect_stdout(f):
print('foobar')
print(12)
print('Got stdout: "{0}"'.format(f.getvalue()))
当这段代码运行的时候, 在with块中真正的print调用不会在屏幕上产生任何东西, 并且你会看到它们的输出被流f捕捉了.
顺便, 注意with语句非常适合这个目的–块里的所有东西都被重定向了; 一旦块结束, 东西都被清空重定向也停止了.
如果你被困在较老的一点也不酷的早于 3.4 的 Python 里1, 该怎么办呢? 好吧, redirect_stdout真的很容易实现.
我会改一点名字来避免混淆:
1
2
3
4
5
6
7
8
9
10
from contextlib import contextmanager
@contextmanager
def stdout_redirector(stream):
old_stdout = sys.stdout
sys.stdout = stream
try:
yield
finally:
sys.stdout = old_stdout
然后我们回到之前的游戏:
1
2
3
4
5
f = io.StringIO()
with stdout_redirector(f):
print('foobar')
print(12)
print('Got stdout:"{0}"'.format(f.getvalue()))
重定向 C 级别的流
现在, 让我们的重定向为了一个更有挑战性的目标前进.
1
2
3
4
5
6
7
8
9
import ctypes
libc = cyptes.CDLL(None)
f = io.StringIO()
with stdout_redirector(f):
print('foobar')
print(12)
libc.puts(b'this comes from C')
os.system('echo and this is from echo')
print('Got stdout:"{0}"'.format(f.getvalue()))
我使用ctypes来直接调用C语言库的puts函数2. 这模拟了当我们在 Python 代码里调用 C 代码打印到stdout的时候会发生什么–同样适用于使用 C 扩展的 Python 模块.
另外os.system调用一个子进程, 这个子进程同样打印到stdout. 这样我们可以得到:
1
2
3
4
5
this comes from C
and this is from echo
Got stdout: "foobar
12
"
呃… 不好. print如愿重定向了, 但是puts和echo的输出越过了我们的重定向并且没有在终端中结束而没有被捕捉. 怎么办?
为了明白这为什么没有起作用, 我们首先需要明白 Python 中的 sys.stdout 究竟是什么.
绕道–关于文件描述符和流
这个部分深入到一些操作系统, C 语言库和 Python 的内部3. 如果你只是想知道怎么在 Python 中合适地从 C 重定向输出, 你可以跳到下一个部分(尽管明白重定向是 怎样 工作的可能会有点困难).
文件是被操作系统打开的, 操作系统保存了一张表, 记录了全系统打开的文件, 其中的一些可能指向相同的底层磁盘数据(两个进程可以在同时打开同一个文件, 每个进程从不同的地方读取, 等等).
文件描述符 是另一个抽象化, 它管理每个进程. 每个进程有它自己的文件描述符的表, 这个表指向那个全系统的表.
这里有一个概述, 来自 Linux系统编程手册 :
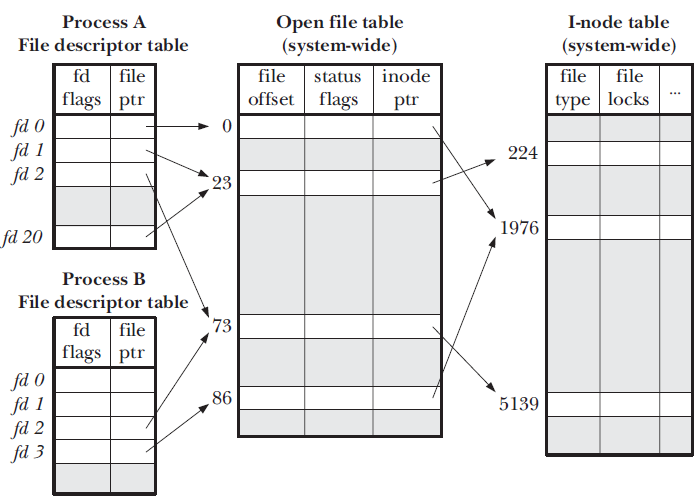
文件描述符允许进程间共享打开的文件(例如, 当使用fork创建子进程的时候). 它们同样对重定向一个输入到另一个有用, 这和这篇文章有关.
假设我们使得文件描述符5是文件描述符4的一个副本. 那么所有对5的写入将会同样写入到4.
再加上在Unix中, 标准输出只是另一个文件描述符(通常是索引1), 你可以知道将会发生什么.
完整的代码在下一部分中给出.
然而文件描述符并不是这个故事的结尾. 你可以使用系统调用read和write来读写它们, 但这并不是常见的做法.
C 运行库提供了一个围绕文件描述符-流的方便的抽象. 它们作为不透明的FILE结构体和一系列作用于其上的函数暴露给程序员(如fprintf和fgets).
FILE是一个相对复杂的结构体, 但更重要的是知道它保存了一个文件描述符, 真正的系统调用被定向到这个文件描述符, 而且它提供了缓冲, 来保证系统调用(很昂贵)不会被经常调用.
假设你发出的是二进制文件, 一次一或两个字节. 使用write无缓冲地写入文件描述符会相当昂贵, 因为每次写入都调用一次系统调用.
在另一方面, 使用fwrites就便宜得多, 因为这个函数典型的调用只是把你的数据复制到它的内部缓冲区中并且推进一个指针.
只有偶尔(取决于缓冲区大小和标志)会有一次真正的write系统调用.
知道了这些信息之后, 就很容易理解对于 C 程序来说stdout究竟是什么了. stdout是一个全局的FILE对象, 由 C 语言库为我们保存, 并且它把文件描述符1的输出缓冲起来. 调用类似printf和puts的函数就会把增加缓冲区的数据. fflush强迫它把缓冲区数据刷到文件描述符, 等等.
但是我们在这里讨论的是 Python 而不是 C. 那么 Python 是怎么把sys.stdout.write的调用转换成真正的输出?
Python 使用底层文件描述符之上的自己的抽象–一个文件对象.
另外, 在 Python 3 中这个文件对象进一步被包裹成一个io.TextIOWrapper, 因为我们传递给print的是一个 Unicode 字符串, 但是底层write系统调用接受的是二进制数据, 所以需要有编码转换.
从这里得到的另一个很重要的是: Python 和它加载的 C 扩展(这与通过ctypes调用的 C 代码同样有关)在同一个进程中运行, 并且为标准输出共享底层的文件描述符.
然而, Python 有它自己更高层的包装器–sys.stdout, 而 C 代码使用它自己的FILE对象. 所以, 简单地用sys.stdout替换从原则上并不能影响 C 代码的输出.
为了更深地替换, 我们不得不接触到 Python 和 C 运行时共享的东西–文件描述符.
使用文件描述符副本来重定向
事不宜迟, 这里是一个改进的stdout_redirector, 同样重定向了 C 代码的输出4:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
from contextlib import contextmanager
import ctypes
import io
import os, sys
import tempfile
libc = ctypes.CDLL(None)
c_stdout = ctypes.c_void_p.in_dell(libc, 'stdout')
@contextmanager
def stdout_redirector(stream):
# The original fd stdout points to. Usually 1 on POSIX systems.
original_stdout_fd = sys.stdout.fileno()
def _redirect_stdout(to_fd):
"""Redirect stdout to the given file descriptor."""
# Flush the C-level buffer stdout
libc.fflush(c_stdout)
# Flush and close sys.stdout - also closes the file descriptor (fd)
sys.stdout.close()
# Make original_stdout_fd point to the same file as to_fd
os.dup2(to_fd, original_stdout_fd)
# Create a new sys.stdout that points to the redirected fd
sys.stdout = io.TextIOWrapper(os.fdopen(original_stdout_fd, 'wb'))
# Save a copy of the original stdout fd in saved_stdout_fd
saved_stdout_fd = os.dup(original_stdout_fd)
try:
# Create a temporary file and redirect stdout to it
tfile = tempfile.TemporaryFile(mode='w+b')
_redirect_stdout(tfile.fileno())
# Yield to caller, then redirect stdout back to the saved fd
yield
_redirect_stdout(saved_stdout_fd)
# Copy contents of temporary file to the given stream
tfile.flush()
tfile.seek(0, io.SEEK_SET)
stream.write(tfile.read())
finally:
tfile.close()
os.close(saved_stdout_fd)
这里有很多细节(如管理输出被重定向的临时文件)可能掩盖了关键方法: 使用dup和dup2来操纵文件描述符.
这些函数使我们可以复制文件描述符并且让任意描述符指向任意文件.
我不会再花时间在它们上面–如果你感兴趣的话, 去读它们的文档. 绕道的那一部分已经提供了足够的背景信息来理解它.
让我们试试这个:
1
2
3
4
5
6
7
8
f = io.BytesIO()
with stdout_redirector(f):
print('foobar')
print(12)
libc.puts(b'this comes from C')
os.system('echo and this is from echo')
print('Got stdout: "{0}"'.format(f.getvalue().decode('utf-8')))
得到的结果:
1
2
3
4
5
Got stdout: "and this is from echo
this comes from C
foobar
12
"
成功了! 有一些需要注意的东西:
-
输出的顺序可能不是我们期望的. 这是因为缓冲. 如果需要保留不同种类输出之间的顺序的话(比如 C 和 Python), 那么还需要更多的工作来禁用所有相关的流缓冲.
-
你可能想知道为什么
echo的输出最终被重定向了? 答案是文件描述符通过子进程被继承. 既然我们在创建子进程执行echo之前操纵了文件描述符1指向我们的文件而不是标准输出, 那么这就是它输出到的地方. -
我们在这里使用了
BytesIO. 这是因为在最底层, 文件描述符是二进制的. 从临时文件复制到指定流的时候它可能做了解码工作, 但是隐藏了一些问题. Python 有自己对Unicode的内存理解, 但是谁知道什么是底层 C 代码的输出数据的正确解码呢? 这就是为什么这个特定的重定向方法把解码留给了调用者. -
上面这些使得这段代码限定于 Python 3. 并没有包括任何魔法, 并且迁移到 Python 2是很琐细的, 但是这里做的一些假设并不成立(比如
sys.stdout是一个io.TextIOWrapper).
重定向子进程的输出
我们已经看到文件描述符副本方法使得我们也可以捕捉到子进程的输出. 但是这并不总是达到这个目的最方便的方法.
在大多数情况下, 你使用subprocess模块来执行子进程, 并且你可能在一个管道中执行多个这样的子进程或者分开执行.
一些程序甚至会判断在多个线程中这样运行的多个子进程. 另外, 当这些子进程在运行的时候你可能想输出什么东西, 而且你不希望这个输出被捕捉到.
所以, 管理stdout文件描述符在大多数情况下可能会很麻烦; 它并不是必不可少的, 因为还有简单得多的方法.
subprocess模块的瑞士军刀Popen类(它为这个模块其余的大部分提供基础服务)接受一个stdout参数, 我们可以用它来接触到子进程的标准输出:
1
2
3
4
5
6
import subprocess
echo_cmd = ['echo', 'this', 'comes', 'from', 'echo']
proc = subprocess.Popen(echo_cmd, stdout=subprocess.PIPE)
output = proc.communicate()[0]
print('Got stdout: ', output)
subprocess.PIPE参数可以用来设置实际的子进程管道(shell), 但是在它最简单的用法中它捕获了子进程的输出.
如果你一次只执行一个子进程, 并且对它的输出感兴趣, 那么还有更简单的方法:
1
2
output = subprocess.check_output(echo_cmd)
print('Got stdout:', output)
checkout会捕获并且返回子进程的标准输出给你; 如果子进程以非零的返回码退出, 它也会抛出一个异常.
总结
我希望覆盖到了 Python 中大多数常见的”标准输出重定向”的场景.
自然地, 这些也都适用于其他标准输出流–stderr. 并且, 我希望文件描述符的背景知识足够清晰来解释返回码; 把这个话题压缩成这么点空间也是一个挑战.
如果还有任何问题遗留或者有什么我可以解释得更好的话请让我知道.
最后, 虽然它的概念简单, 重定向的代码却相当长; 我很乐意知道如果你发现了一个更短的方法来实现同样的效果.
-
不要绝望. 直到2015年2月, 全世界相当多的 Python 程序员都在同一条船上. ↩
-
注意传递给
puts的 字节. 这是 Python 3, 我们不得不小心因为libc并不理解 Python 的 unicode 字符串. ↩ -
下面的描述集中在 Unix/POSIX 系统; 并且这是必然的部分. 大的书本章节已经写了这个话题–我只是试着展示与流重定向相关的一些关键概念. ↩
-
这里采取的方法是受 Stack Overflow answer 的启发. ↩