Please stop calling databases CP or AP
在 Jeff Hodges 著名的博客文章 Notes on Distributed Systems for Young Bloods 中, 他推荐我们使用 CAP 定理 来评判系统. 很多人都把这个建议谨记在心, 把他们的系统描述为 “CP”(在网络分区中满足一致性但不满足可用性), “AP”(在网络分区中满足可用性但不满足一致性), 或者有时候是 “CA”(意味着我还没读几乎五年前的 Coda 的文章).
我同意 Jeff 其他的所有观点, 但对于 CAP 定理, 我必须不同意. CAP 定理太过简单并且被普遍误解为是用来定义系统特征的. 因此, 我想请求大家抛弃所有对 CAP 定理的引用, 停止讨论 CAP 定理, 把这个可怜的东西放到一边. 相反, 我们应该用更精确术语来说明我们的取舍.
(是的, 我意识到了写这样一篇博客文章的讽刺意味, 因为这正是我请求大家不要再写的话题. 但是至少它给了我一个 URL 这样我可以给出大家理由说明我为什么不喜欢大家讨论 CAP 定理. 同时, 如果这篇文章有点胡说八道的话我道歉, 不过至少这是一篇有大量参考文献的胡说八道.)
CAP 使用非常狭隘的定义
如果你想把 CAP 当作一个定理(而不是你数据库的营销材料中的一个模糊的空洞概念), 那么你就必须精确. 数学需要精确. 只有在你使用的词语和他们在 这个证明 中使用的词语意思相同时, 这个证明才立得住脚. 而且这个证明使用非常具体的定义:
-
CAP 中的一致性通常意味着线性化, 这是非常具体(并且非常强健)的一致性的概念. 尤其是它和 ACID 中的 C 没有半毛钱关系, 即使 C 也代表”一致性”. 我会在下面解释线性化的意思.
-
CAP 中的可用性被定义为”系统中的一个非失败的[数据库]节点接收的每一个请求都必须回复一个[非错误的]响应”. 对于某些可以处理如下请求的节点来说这是不够的: 任意 非失败的节点必须可以处理它. 许多所谓的”高可用性”(如低宕机)系统实际上不能满足这个可用性的定义.
-
容忍网络分区(可怕的错误命名)基本上意味着你在一个可能延迟或丢信息的异步网络上通信. 互联网和我们所有的数据中心都有这个属性, 所以你在这个问题上其实毫无选择.
同样注意, CAP 定义不只是描述了任何旧系统, 它也是系统的一个非常具体的模型:
-
CAP 系统模型是一个单独的, 读写寄存器–就是这些. 例如, CAP 定理没有说任何关于涉及多个对象的事务: 它们只是不在这个定理的范围内, 除非你可以把它们化简成一个单独的寄存器.
-
CAP 定理考虑的唯一错误是网络分区(如节点一直在线而它们之间的部分网络却无法工作). 这种错误确实完全可能发生, 但它不是唯一可能出错的事情: 节点可能会崩溃或者重启, 你可能会用光磁盘空间, 可能会遇到软件中的一个 bug 等等. 在构建分布式系统中, 你需要考虑更广泛的取舍, 并且太过注重 CAP 理论会导致忽略其他重要问题.
-
同时, CAP 定理没有讨论延迟, 人们对延迟的关注程度要高于可用性. 事实上, CAP 可用的系统被允许任意地延迟响应, 并且仍然被叫做”可用性”. 冒着被指责的风险, 如果需要两分钟来载入一个页面的话, 我猜你们的用户并不会把你们的系统叫做”可用性”.
如果你使用的词语符合这个证明的精确定义, 那么 CAP 定理就适用于你. 但如果你使用了其他的一致性或可用性的概念, 那么你不能期望 CAP 定理同样适用. 当然, 这并不意味着你仅仅通过重新定义一些词语就可以突然做成不可能的事情! 它只意味着你不能再向 CAP 定理请求指导, 并且你不能使用 CAP 定理来调整你的观点.
如果 CAP 定理不适用, 这意味着你不得不自己取舍. 你可以用你自己对这些词的定义来理论一致性和可用性, 并且很欢迎你证明自己的定理. 但请不要把它叫做 CAP 定理, 因为这个名字已经被占用了.
线性化
以防你对线性化(也就是 CAP 中的”一致性”)不熟悉, 先让我简单地解释一下. 正式定义并不简单, 但主要观点, 非正式地说, 就是:
如果操作 B 在 操作 A 成功完成之后开始, 那么操作 B 看见的系统状态必须和操作 A 刚完成时的状态一样或者更新.
为了使这个更明确, 考虑一个不能线性化的示例系统. 看下图(我的书中一个还未发布章节的先睹为快):
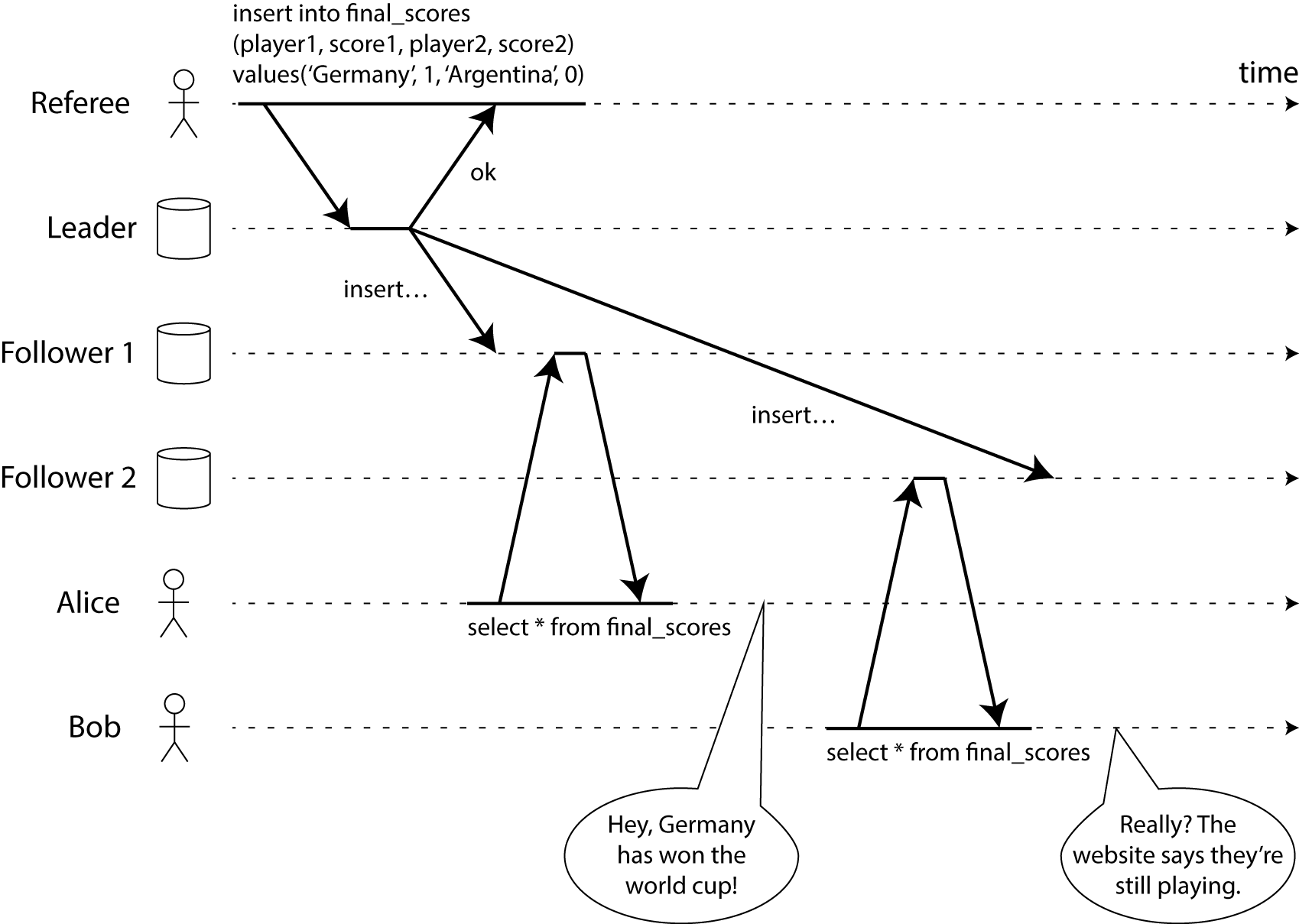
这个图画了在同一个房间里的 Alice 和 Bob, 都在检查他们的手机来查看2014足球世界杯的结果. 正好在最终结果宣布的时候, Alice 刷新了这个页面, 看到宣布了冠军, 并且激动地告诉了 Bob. Bob 难以置信地 重载 了他自己的手机, 但他请求到的数据库是一个滞后的副本, 所以他的手机显示比赛还在继续.
如果 Alice 和 Bob 同时刷新页面, 那么如果他们得到两个不同的查询结果的话并不会令人惊讶, 因为他们不知道他们各自的请求到底是在哪个时刻被服务器处理的. 然而, Bob 知道他是在听到 Alice 说了最终结果 之后 才点击的刷新按钮, 并且因此期待他的查询结果至少和 Alice 的一样. 结果他得到了一个过期的查询结果, 这是违反线性化的.
知道 Bob 的请求是严格地在 Alice 的请求之后发生的(如他们并不是并行的), 是取决于 Bob 通过一个其他的通信频道(在这种情况下是IRL音频) 听到了 Alice 的请求结果.如果 Bob 没有从 Alice 那里听到比赛结算了, 那么他并不会知道他的查询过期了.
如果你在构建一个数据库, 你不知道你的用户可能会有哪些种类的反向通信. 因此, 如果你想在你的数据库中提供可线性化的语义(CAP-一致性), 你需要让它表现得像只有一份数据副本一样, 即使在多个地方可能有多个数据副本(副本, 缓存).
如果提供的话这是一个相当昂贵的保证, 因为它需要大量的协作. 甚至你计算机的 CPU 没有提供可线性化地访问你的本地内存的方法! 在现代 CPUs 中, 你需要一个显式的内存隔离指令来得到线性化. 并且甚至测试一个系统是否提供线性化也很棘手.
CAP-可用性
让我们简单地讨论一下在网络分区的情况下是放弃线性化还是放弃可用性的需求.
假设你在两个不同的数据中心有你的数据库的多个副本. 复制的具体方法暂时并不重要–可能是单主(master/slave), 多主(master/master)或基于仲裁的复制(Dynamo风格). 复制的需求是无论何时数据被写入一个数据中心, 那么它也要被写入另一个数据中心, 当复制发生时在两个数据中心之上必须有网络连接.
现在假设网络连接中断了–也就是我们说的一个 网络分区. 会发生什么呢?
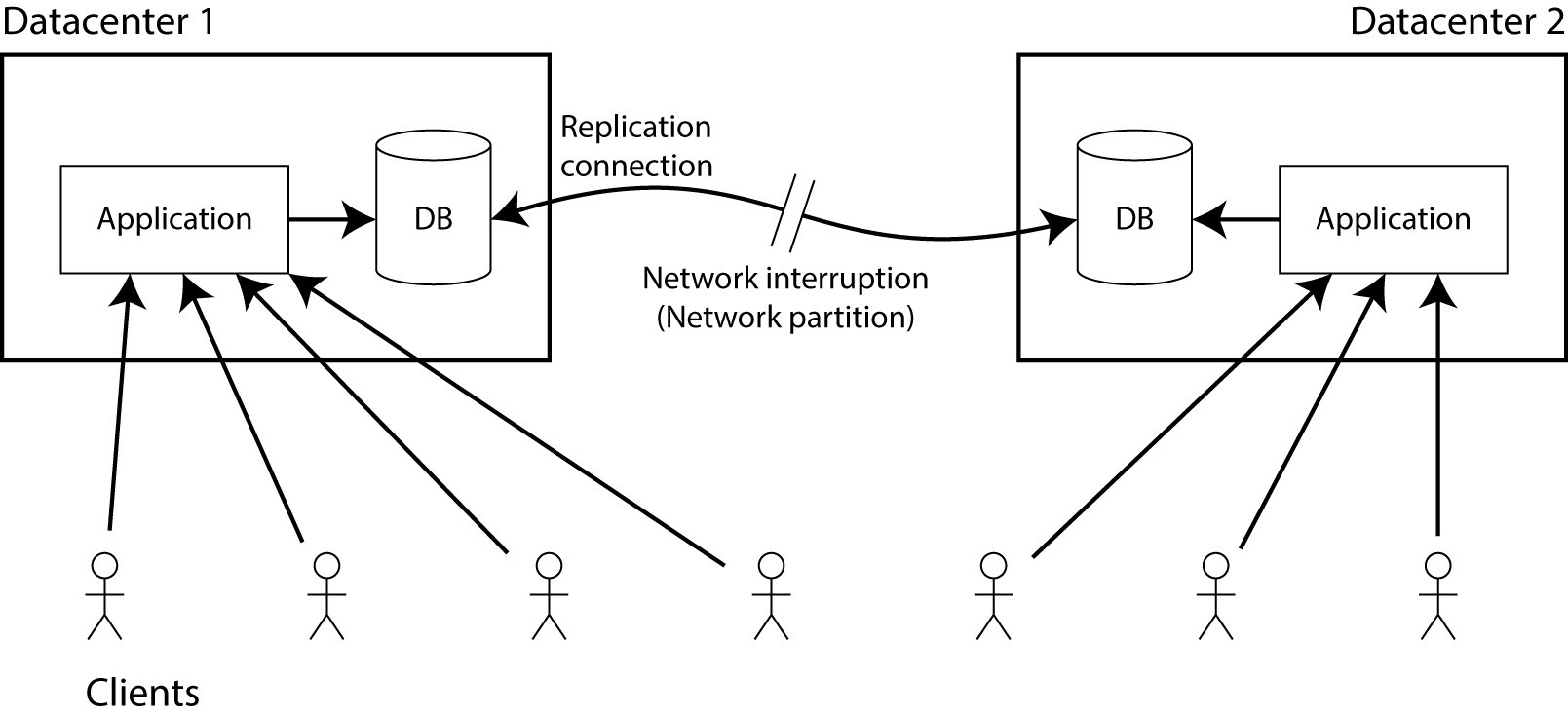
显然你可以选择下面两个中的一个:
-
应用仍然允许继续写入到数据库, 那么它仍然在两个数据中心中保持完全可用性. 但是, 只要复制连接是中断的, 任何写入到一个数据中心的改变将不会在另一个数据中心发生. 这违反了线性化(就前面的例子而言, Alice 可能连接到 DC1 而 Bob 可能连接到 DC2).
-
如果你不想失去线性化, 那么你不得不保证所有的读写都在一个数据中心, 你可能把它叫做 leader. 在另一个数据中心(因为复制连接故障, 它不能被更新), 数据库必须停止接受读写直到网络分区被恢复并且数据库再一次同步. 因此, 尽管这个非主的数据库没有发生故障, 它仍然不能处理轻轻, 所以它不是 CAP-可用性的.
(顺便一提, 这本质上是 CAP 定理的证明. 就是这么回事儿. 这个例子使用了两个数据中心, 但它等同于一个数据中心下的网络问题. 我只是发现两个数据中心比较好理解.)
注意, 在选项2中名义上的”不可用”情况, 我们仍然在一个数据中心里处理请求. 所以如果一个系统选择了线性化(而不是CAP-可用性), 并不一定意味着一个网络分分区自动地导致了应用中断. 如果你可以把所有客户端转换成使用主数据中心, 那么客户端实际上感受不到任何宕机.
实际上的可用性并不完全对应于 CAP-可用性. 你的应用的可用性可能通过一些 SLA(如99.9%的完整请求必须在1秒之内返回一个成功的响应)来测量, 但这样一个 SLA 可能同样适用于 CAP-可用和 CAP-不可用的系统.
实际上, 多数据中心的系统 都 通常用异步复制来设计, 因此是非线性化的. 然而, 这样选择的理由通常是大面积网络的延迟, 而不是仅仅希望容忍数据中心和网络故障.
很多系统既不是可线性化的也不是 CAP-可用的
在 CAP 定理对一致性(可线性化)和可用性的严格定义下, 系统怎样取舍?
例如, 考虑任意有一个 leader 的复制数据库, 这是在大多数关系型数据库中设置副本的标准方法. 在这个配置中, 如果一个客户端从 leader 被分出来, 它就不能写入数据库. 即使它可以从一个 follower(一个只读副本)中读取数据, 它不能写入意味着任意单个 leader 的设置都是非 CAP-可用的. 不要介意这种配置通常被叫做”高可用性”.
如果单个 leader 的复制不是 CAP-可用的, 那么它是”CP”吗? 等等, 别这么快. 如果你允许这个副本从一个 follower 中读取数据, 并且这个副本是异步的(大多数数据库默认), 那么当你读取的时候一个 follower 可能会比 leader 稍微落后一点点, 你的读取将不会是可线性化的, 既不是 CAP-一致的.
另外, 有快照隔离/MVCC 的数据库是故意非线性化的, 因为强制线性化可能会降低数据库可以提供的并发级别. 例如, PostgreSQL 的 SSI 提供序列化但不是线性化吗, 而 Oracle 提供的则相反. 只是因为一个数据库被烙上 “ACID” 并不意味着它符合 CAP 定理定义中的一致性.
所以这些系统既不是 CAP-一致的, 也不是 CAP-可用的. 它们既不是 “CP” 也不是 “AP”, 只是 “P”, 不管这意味着什么. (是的, 这个”三取二”的说法并不允许你只取三个当中的一个, 或者不取三个中的任何一个!)
那么 “NoSQL” 呢? 考虑 MongoDB, 例如: 它每一片有一个 leader(或至少假设是这样, 如果它不是在脑裂的模式下), 所以通过上面的论述它不是 CAP-可用的. 并且 Kyle 最近展示了 它允许非线性的读取即使在最高的一致性设置的情况下, 所以它也不是 CAP-一致的.
Dynamo 的衍生如 Riak, Cassandra 和 Voldemort, 哪一个通常被叫做 “AP” 既然它们对高可用性做了优化? 这取决于你的设置. 如果你接受一个副本用来读写(R=W=1), 那它们确实是 CAP-可用的. 然而, 如果你仲裁读写(R+W>N), 那么你就有一个网络分区, 在分区的少数一方的客户端就不能得到一个仲裁, 所以仲裁操作不是 CAP-可用的(至少暂时是, 直到数据库在少数一方设置额外的副本).
你有时候会看到有人声称仲裁读写保证了可线性化, 但是我认为依赖它是不明智的–特征的微妙组合如草率仲裁和读修复可能导致棘手的边界情况, 在这种情况下已删除的数据会被恢复, 或者某个值的副本数目少于最初的 W (违反了仲裁条件), 或者副本节点的数目超过了最初的 N (再一次违反了仲裁条件). 所有这些都导致了非线性化的结果.
这些不是坏系统: 人们一直在生产环境中成功地使用它们. 然而, 到目前为止我们还不能严格地把他们划分成 “AP” 或 “CP”, 既是因为它取决于具体的操作或配置, 又是因为这个系统满足不了 CAP 定理对一致性和可用性的严格定义.
样例学习: ZooKeeper
那么 ZooKeeper 呢? 它使用一个一致性算法, 所以人们普遍把它当作一个在可用性之上明确选择一致性的情况(即一个 “CP 系统”).
然而, 如果你看一下 ZooKeeper 的文档, 明确指出 ZooKeeper 默认不提供可线性化的读. 每个连接到这个服务器某个节点的客户端, 当你读数据的时候, 你只能读到那个结点的数据, 即使其他节点有最新写入的数据. 这使得读取数据比不得不仲裁或在每次读的时候请求 leader 的情况要快得多,但也意味着 ZooKeeper 默认不符合 CAP 定理对一致性的定义.
在读取数据前用一个sync命令可以使得 ZooKeeper 可线性化地读取数据. 但这并不是默认的, 因为这样会遇到一个性能损失. 人们确实使用sync命令, 但并不是一直使用.
那么 ZooKeeper 的可用性呢? 好吧, ZooKeeper 要求一个大多数仲裁来达到一致性, 如为了处理写数据. 如果你一个分区有大多数节点在一边, 少部分在另一边, 那么大多数的一边会继续发挥作用, 而少数的那一边不能再处理写入, 即使这些节点在线. 因此, ZooKeeper 中的写入在一个分区内不是 CAP-可用的(即使大多数的一边可以继续处理写入).
为了助兴, ZooKeeper 3.4.0 增加了一个只读模式, 在这种模式下分区少数一边的节点可以继续服务读请求–不需要仲裁! 这个只读模式是 CAP-可用的. 因此, ZooKeeper 默认既不是 CAP-一致的(CP)也不是 CAP-可用的(AP)–它只是 “P”. 然而, 如果你想的话可以通过调用sync把它变成 CP, 并且如果你打开了正确的选项, 对于读(但不是写)它真正是 AP.
但这很恼人. 把 ZooKeeper 叫做”不一致的”仅仅因为它默认不是可线性化的, 实在是严重歪曲了它的特性. 它实际上提供了一个出色的一致性级别! 它提供原子广播(这可以简化为一致性)并和因果一致性的会话保证相结合–这比read your writes, monotonic reads和consistent prefix read相结合更强大. 文档说它提供顺序一致性, 但它在推销自己, 因为 ZooKeeper 的保证实际上比x顺序一致性强大得多.
就像 ZooKeeper 论证的, 一个系统在分区的存在下既不是 CAP-一致的也不是 CAP-可用的是非常合理的, 并且在 没有 分区的情况下也默认不是可线性化的. (我猜这可能是 Abadi’s PACELC 框架 中的 PC/EL, 但我没有找到比 CAP 更有启发性的.)
CP/AP: 一个错误的二分法
我们不能把即使一个数据存储明确地分为 “AP” 或 “CP” 的事实应该告诉我们一些东西: 这些不是用来描述系统的合标签.
我相信我们应该停止把u数据存储分成 “AP” 或 “CP”, 因为:
-
在软件的一片内, 你可能对不同的一致性特性有不同的操作.
-
在 CAP 定理的定义下很多系统既不是一致的也不是可用的. 然而, 我从来没听过有人把他们的系统仅仅叫做 “P”, 想必是因为它看上去很糟糕. 但它不是糟糕–它可能是非常合理的 设计, 它只是不适合 CP/AP 中的任何一个.
-
即使大多数软件并不完全适合这两种分类, 人们仍然试着把软件分成这两类中的一个, 因此必将把”一致性”或”可用性”的意思改变成适合它们的定义. 不幸的是, 如果这个词的意思改变了, CAP 定理就不再适用了, 因此 CP/AP 的区别变得完全没有意义.
-
把一个系统分为这两类使得系统失去了大量的精妙之处. 设计一个可分布式系统的时候有很多关于容错, 延迟, 编程模型简化, 可操作性等等的考虑.例如, 即使 ZooKeeper 有一个 “AP” 只读模式, 这个模式仍然提供了一个完全的历史写入顺序, 这极大地加强保证了 Riak 或 Cassandra 这样的系统中 “AP” – 所以把它们放到同一类里是很可笑的.
-
即使 Eric Brewer 承认 CAP 是误导人的并且过分简化了. 在2000年, 它意味着开始一个关于在分布式系统中做取舍的讨论, 并且它做得非常好. 它并没有打算成为一个突破性的正是结果, 它也没打算成为一个n数据系统严格的分类方案. 15年之后, 我们现在有更多更好的工具处理不同的一致性以及更多更好的容错模型的选择. CAP 已经完成了它的目标, 现在是时候前进了.
学会自己思考
如果 CP 和AP 都不适用于描述和评判系统, 那么应该用什么代替呢? 我不认为这有一个正确的答案. 很多人对这类问题思考了很多, 并且提出了术语和模型来帮助我们理解问题. 为了学习这些观点, 你需要更深入地了解文献.
-
一个好的开始是 Doug Terry 的论文, 他在这篇论文里用棒球的例子解释了各种不同级别的最终一致性. 这篇论文非常有可读性并且很清晰, 即使(像我一样)你不是美国人并且没有棒球知识.
-
如果你对事务独立模型(这和分布式副本的一致性不同, 但是有点联系)感兴趣, 我的小项目Hermitage可能相关.
-
副本和一致性, 事物独立性以及可用性之间的联系由 Peter Bailis et al探讨过. (这篇文章也解释了 Kyle Kingsbury 希望展示的一致性层次结构的意义).
-
当你已经读完了这些, 你应该已经准备更深入地了解文献了. 我在这篇文章中已经收集了几吨的文献链接. 一定要读一读它们: 很多专家已经帮你做了很多事情.
-
最后一招, 如果你不忍直视阅读这些原始论文, 我建议你看一看我的书, 它以平易近人的方式总结了这些最重要的观点.(你看, 我已经 非常努力 地让这篇文章推销我的书.)
-
如果你想知道更多具体关于正确使用 ZooKeeper 的东西, Flavio Junqueira 和 Benjamin Reed 的书很棒.
无论你选择哪种方式学习, 我鼓励你一定要认真并且有耐心–学习这些并不容易. 但是它是有意义的, 因为你学会说明取舍的原因, 并且因此弄明白了哪种架构最适合你的应用. 但是无论你做什么, 请停止讨论 CP 和 AP, 因为它们并没有任何意义.
comments powered by Disqus